云計算的編程模式與數據處理及存儲支持服務
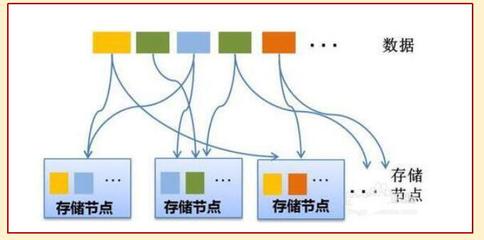
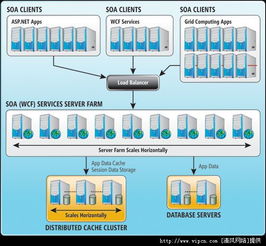
隨著云計算技術的迅速發展,其編程模式以及數據處理和存儲支持服務已成為現代IT架構的核心組成部分。云計算不僅改變了應用開發和部署的方式,還提供了彈性、可擴展的資源管理方案。本文將探討云計算的編程模式,并分析其在數據處理和存儲支持服務中的應用。
一、云計算的編程模式
云計算的編程模式主要針對分布式、大規模計算環境設計,旨在簡化開發流程、提高資源利用效率。常見的編程模式包括:
- MapReduce 模式:由 Google 提出,廣泛應用于大數據處理。該模式將任務分解為 Map(映射)和 Reduce(歸約)兩個階段,允許開發者在分布式集群上并行處理海量數據,而無需關注底層硬件細節。例如,Hadoop 框架就基于此模式,幫助企業在云端處理日志分析、數據挖掘等任務。
- 事件驅動編程模式:在云計算中,事件驅動模式常用于無服務器計算(Serverless Computing),如 AWS Lambda 或 Azure Functions。開發者只需編寫函數代碼,云平臺自動處理事件觸發和資源分配,實現高伸縮性和成本優化,適用于實時數據處理、IoT 應用等場景。
- 微服務架構模式:云環境鼓勵將單體應用拆分為獨立的微服務,每個服務可獨立部署、擴展和管理。通過容器技術(如 Docker)和編排工具(如 Kubernetes),微服務模式在云中提升了應用的可維護性和靈活性,支持敏捷開發和持續交付。
- 數據流編程模式:這種模式專注于連續數據處理,適用于實時分析場景。例如,Apache Kafka 和 Apache Flink 在云端構建數據流管道,支持事件處理和復雜事件檢測,幫助企業快速響應市場變化。
這些編程模式共同推動了云計算的普及,使開發者能夠高效利用云資源,同時降低運維復雜度。
二、數據處理支持服務
云計算平臺提供了豐富的服務來支持數據處理,涵蓋數據獲取、處理、分析和可視化等環節:
- 數據集成與 ETL 服務:云服務如 AWS Glue 和 Google Cloud Dataflow 提供自動化的數據提取、轉換和加載(ETL)功能,幫助用戶整合來自不同來源的數據,為分析做好準備。
- 大數據分析服務:例如,Amazon EMR 或 Google BigQuery 允許用戶在云端運行大規模數據分析作業,無需管理底層集群。這些服務支持 SQL 查詢、機器學習集成,適用于商業智能和預測分析。
- 實時處理服務:云平臺提供的流處理服務,如 Azure Stream Analytics,能夠實時處理數據流,支持監控、報警和即時決策,廣泛應用于金融交易、社交媒體分析等領域。
通過這些服務,企業可以在云中構建端到端的數據處理管道,實現從原始數據到洞察的快速轉化。
三、存儲支持服務
云存儲是云計算的基礎,提供多種存儲類型以滿足不同需求:
- 對象存儲:例如 Amazon S3 或 Google Cloud Storage,適用于存儲非結構化數據,如圖片、視頻和備份文件。它具有高持久性、可擴展性和低成本的特點,常與數據處理服務結合使用。
- 塊存儲:如 AWS EBS 或 Azure Disk Storage,提供類似傳統硬盤的塊級存儲,適用于數據庫和虛擬機等需要高性能 I/O 的應用。
- 文件存儲:服務如 Amazon EFS 或 Google Filestore,提供共享文件系統,支持多實例訪問,常用于協作應用和內容管理系統。
- 數據庫服務:云平臺還提供托管數據庫服務,包括關系型數據庫(如 Amazon RDS)和 NoSQL 數據庫(如 Google Firestore),這些服務自動化了備份、擴展和安全,簡化了數據管理。
四、整合與應用案例
在實際應用中,云計算的編程模式與數據處理、存儲服務緊密集成。例如,一家電商公司可能使用微服務架構部署應用,利用事件驅動模式處理用戶訂單事件,并將數據存儲在對象存儲中;通過 MapReduce 模式分析銷售數據,生成實時報表。這不僅提升了系統性能,還降低了總體擁有成本(TCO)。
云計算的編程模式和數據處理、存儲支持服務共同構成了一個強大的生態系統,推動了數字化轉型。隨著人工智能和邊緣計算的融合,這些服務將進一步演進,為企業創新提供更多可能。開發者應持續學習相關技術,以充分利用云計算的優勢。
如若轉載,請注明出處:http://www.wuxianhome.com/product/16.html
更新時間:2026-03-13 12:51:28