MySQL如何實現萬億級數據存儲與數據處理及存儲支持服務
隨著大數據時代的到來,企業面臨的數據量急劇增長,萬億級數據存儲和處理成為關鍵挑戰。MySQL作為廣泛使用的關系型數據庫,雖然傳統上在單機場景下處理大規模數據存在性能瓶頸,但通過合理架構設計和優化,可以實現萬億級數據的存儲與高效處理。以下將詳細介紹MySQL實現這一目標的策略,并探討相關的數據處理與存儲支持服務。
一、MySQL實現萬億級數據存儲的策略
1. 分庫分表(Sharding):
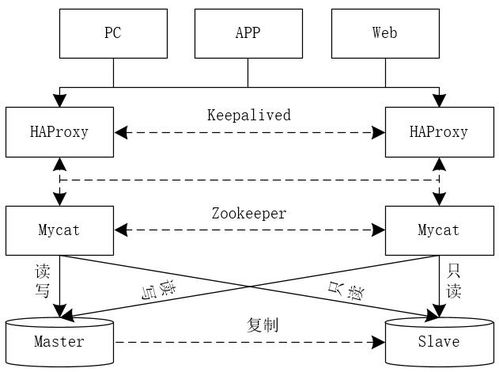
分庫分表是處理海量數據的核心技術。通過水平拆分,將數據分布到多個數據庫實例或表中,避免單點性能瓶頸。例如,按用戶ID或時間范圍進行分片,每個分片存儲部分數據。工具如MyCat、ShardingSphere可幫助自動化分片管理。
2. 使用分布式存儲引擎:
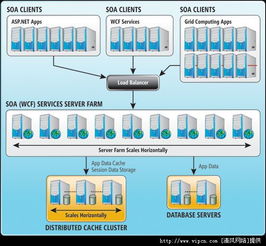
傳統的InnoDB引擎在單機存儲上有限,可結合分布式存儲解決方案,如TiDB(基于MySQL協議的分布式數據庫)或使用MySQL與NoSQL數據庫(如HBase)混合架構,以擴展存儲容量。
3. 數據壓縮與歸檔:
對歷史數據采用壓縮存儲,減少磁盤占用。MySQL支持表壓縮功能(如InnoDB的Barracuda格式),同時可設置歸檔策略,將冷數據遷移到低成本存儲(如對象存儲),熱數據保留在高速存儲中。
4. 優化硬件與配置:
使用高性能SSD硬盤、增加內存以提升緩沖池效率,并調整MySQL配置參數(如innodbbufferpoolsize、innodblogfilesize)以支持更大數據量。分布式部署時,采用負載均衡器(如HAProxy)分發查詢請求。
二、數據處理支持服務
1. 批量處理與ETL工具:
對于萬億級數據,使用ETL(Extract, Transform, Load)工具如Apache Spark、Apache Flink或MySQL自帶的批處理功能,實現數據清洗、轉換和加載。結合消息隊列(如Kafka),實現實時數據流處理。
2. 索引與查詢優化:
設計高效的索引策略(如復合索引、分區索引),避免全表掃描。利用MySQL的查詢緩存和分區表功能(Partitioning),將大表按范圍或列表分區,提升查詢性能。對于復雜分析,可集成OLAP工具(如ClickHouse)。
3. 數據備份與恢復:
采用增量備份和快照技術,結合工具如XtraBackup或Percona Toolkit,確保數據安全。在分布式環境中,實施多副本和容災機制,防止單點故障。
三、存儲支持服務
1. 云服務與托管方案:
利用云平臺(如AWS RDS、阿里云PolarDB)的托管MySQL服務,這些服務自動處理擴展、備份和監控,支持彈性存儲,可輕松應對數據增長。
2. 監控與運維自動化:
部署監控工具(如Prometheus、Grafana)跟蹤數據庫性能,設置報警機制。使用自動化運維工具(如Ansible)管理集群,確保高可用性和可擴展性。
3. 數據安全與合規:
實施加密存儲(如TLS/SSL傳輸、數據加密)、訪問控制和審計日志,滿足GDPR等法規要求,保障萬億級數據的安全。
四、總結
MySQL實現萬億級數據存儲并非易事,但通過分庫分表、分布式架構、優化處理流程和利用云服務,可以有效應對挑戰。結合高效的數據處理與存儲支持服務,企業能夠構建穩定、可擴展的大數據平臺,支持業務持續增長。實際應用中,建議根據具體場景進行測試和調優,以確保性能和成本平衡。
如若轉載,請注明出處:http://www.wuxianhome.com/product/18.html
更新時間:2026-03-13 21:43:36