分布式數據庫設計與實現 數據處理和存儲支持服務
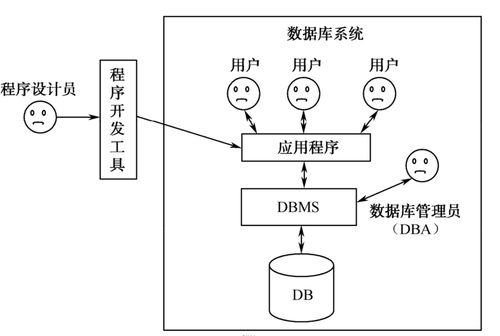
隨著互聯網技術的飛速發展,數據量呈爆炸式增長,傳統的集中式數據庫在擴展性、可靠性和性能方面面臨嚴峻挑戰。分布式數據庫應運而生,它通過將數據分散存儲在多臺獨立的服務器上,提供了高效的數據處理和存儲支持服務。本文將從設計原則、關鍵實現技術以及服務支持三個方面,探討分布式數據庫的核心內容。
一、分布式數據庫設計原則
分布式數據庫的設計旨在滿足高可用性、可擴展性和一致性等需求。數據分片是基礎設計原則,通過水平或垂直分片將數據分布到不同節點,以平衡負載并提高查詢效率。采用冗余備份機制,如副本復制,確保數據在節點故障時不會丟失,提升系統的容錯能力。設計時需考慮一致性協議,例如基于Paxos或Raft的共識算法,以保障分布式環境下數據的一致性。設計應支持彈性伸縮,允許動態添加或移除節點,適應業務量的變化。
二、關鍵實現技術
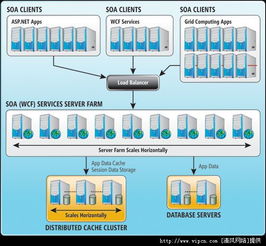
在實現分布式數據庫時,核心技術包括數據分布策略、事務處理和查詢優化。數據分布策略涉及分片鍵的選擇和分布算法,如一致性哈希,以減少數據遷移開銷。事務處理需支持分布式事務,常用方法如兩階段提交(2PC)或基于時間戳的并發控制,確保ACID特性。查詢優化則通過分布式查詢引擎,將全局查詢分解為局部子查詢,并行執行以提高性能。數據存儲層通常采用列式或行式存儲,結合壓縮和索引技術,優化存儲效率和訪問速度。
三、數據處理和存儲支持服務
分布式數據庫不僅提供數據存儲,還集成了強大的數據處理和存儲支持服務。在數據處理方面,它支持實時流處理、批量分析和機器學習集成,例如通過Spark或Flink框架進行復雜計算。存儲服務則包括多副本管理、自動故障恢復和數據生命周期管理,確保數據持久性和可用性。服務層提供監控、備份和安全管理工具,幫助用戶高效運維。例如,云原生分布式數據庫(如Google Spanner或Amazon DynamoDB)還提供了全球分布、低延遲訪問的服務,滿足全球化業務需求。
分布式數據庫的設計與實現是一個系統工程,它通過先進的分片、復制和一致性技術,構建了可靠的數據處理與存儲支持服務。隨著人工智能和物聯網的發展,分布式數據庫將繼續演進,為企業提供更智能、更高效的數據管理解決方案。
如若轉載,請注明出處:http://www.wuxianhome.com/product/19.html
更新時間:2026-03-13 12:30:48